Python爬虫练习
最近感觉没什么好写的,把以前练习Python写的东西记录一下.关于SadPanda和某泥潭的.
没啥技术含量(
Stage1st挂机脚本
某知名
巨魔钓鱼泥潭需要访问几十个小时才能升级加权限,又刚好有闲置的服务器,所以想想办法实现挂机功能
科技就是力量,分析是如何判断登陆的
打开 Edit This Cookie
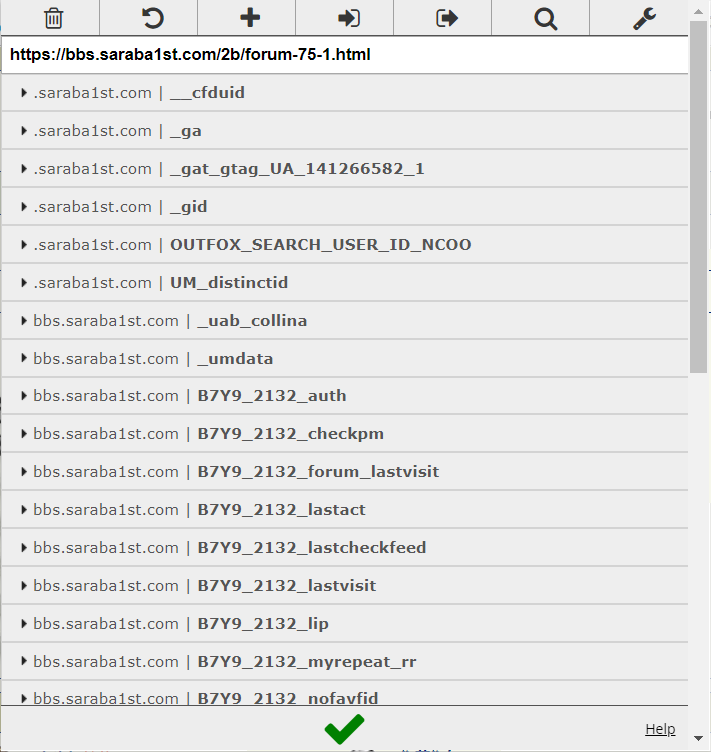
Emm Cookie有点多,不管了 先全部复制进去尝试一下
用requests跑下结果是能用的,登陆状态正常
但是,得分析下哪个Cookie才是真正的身份信息
像一些lastact看起来就没什么用
笨方法,虽然cookie多但是也不是很多
逐个删除,当删了auth后登陆掉了,留下auth,继续操作
发现登陆身份信息判断是用 auth和 slatkey 判断的
request一把梭
import requests
import time
import random
error=0
while 1:
cookie = {
'B7Y9_2132_auth':'This is your auth',
'B7Y9_2132_saltkey':'This is your slatkey'
}
try:
res = requests.get('https://bbs.saraba1st.com/2b/forum-75-1.html',cookies=cookie)
now = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
except:
time.sleep(60)
if res.text.find('Aisina') != -1:
print('['+now+'] '+'Logined')
time.sleep(random.randint(120,480))
if error!=0:
error=0
else:
print('['+now+'] '+'Login failed!')
error=error+1
time.sleep(300)
if error>=3:
break
加点random和等候时间,防止被防火墙拦了
测试有效,完
获取SadPanda收藏的磁力链接
这个项目当时是Ex要倒闭的时候为了抢救下我的收藏写下的(
首先判断Ex是什么方式获取数据的,按下F12,发现是服务端渲染,所以我使用了bs4来解析html数据
先填入 cookie 上requests测试,发现登陆成功
然后就是获取收藏列表里的本子有没有磁力,之前Ex改版过一次,有磁力的在评分右边会有一个绿色的下载箭头
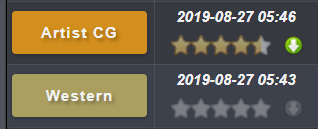
通过这个判断是否有磁力链接,对比两个元素发现可以下载的有title="Show torrents"不能下载的是 title="No torrents available"
bs4 解析搜索获取到下载页面
进入到了下载页面本来想的是做下载种子的,结果发现下载链接长这样
https://sadpanda.org/torrent/1472720/9f195ee0788a64322c2f04e3a608a991cb1f10f.torrent
后面那个明显是磁力链接,所以用 正则匹配一下 用了os.path.splitext和os.path.basename截取下文件名
由于当时赶时间就直接使用print输出了
(后面有加了个多线程
import requests
from bs4 import BeautifulSoup
import time
import os
import threading
header={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
'Cookie':'THIS IS YOUR COOKIE'
}
def getPage(url,header,page=0):
while 1:
try:
ret = requests.get(url+'?page='+str(page),headers=header)
ret.encoding = ret.apparent_encoding
if ret.status_code != 200:
time.sleep(0.3)
else:
return ret
except:
time.sleep(0.3)
def getList(header,i):
subRes = getPage('https://exhentai.org/favorites.php',header,i)
subSoup = BeautifulSoup(subRes.text,'lxml')
findArrary = subSoup.find_all(title="Show torrents")
for r in findArrary:
threading.Thread(target=getMagnet,args=(r.parent['href'],header,)).start()
def getMagnet(url,header):
while 1:
try:
ret = requests.get(url,headers=header)
if ret.status_code != 200:
time.sleep(0.3)
else:
soup = BeautifulSoup(ret.text,'lxml')
link = soup.form.a
print('magnet:?xt=urn:btih:'+os.path.splitext(os.path.basename(link['href']))[0].upper()+"\t"+link.text)
return
except:
time.sleep(0.3)
res = getPage('https://exhentai.org/favorites.php',header)
soup = BeautifulSoup(res.text,'lxml')
page = int(soup.find(class_="ptt").find_all('a')[-2].text)
print("Page:"+str(page))
for i in range(0,page):
threading.Thread(target=getList,args=(header,i,)).start()
测试能用,完
This blog is under a CC BY-NC-SA 3.0 Unported License
Link to this article: https://hex.moe/p/ab67235a/